Data verwerven - webscraping
Data verwerven
- 1. Omgaan met Data - De data pijplijn
- 2. De aansluiting met informatiekunde
- 3. Doel van de sessie
- 4. Alles is een lijstje: gestructureerde en ongestructureerde data
- 5. Straight Data
- 6. Webscraping: 'Your own robot'
- 6-1. Google spreadsheet function importHTML - tables en lists
- 6-2. Wat als de data niet in een tabel of list staat en/of verspreid is over verschillende webpagina's?
- 6-3. Zoeken naar structuur in HTML
- 6-3-1. Screencast Google spreadsheet functies
- 6-4. Voorbeeld waranwiki scraper
- 6-5. Scrapen van meerdere pagina's
- 6-6. Scrapers op maat
- 6-6-1. Voorbeeld complexe scraper
- 6-6-2. Eenvoudiger voorbeeld
- 7. Programmeren = problem-solving
- 8. Oefeningen
- 9. Bronnen
1. Omgaan met Data - De data pijplijn
We werken deze module uit in drie delen - één sessie per deel:
- data vinden/verwerven, aanmaken
- verwerken (converteren, opkuisen, mijnen, analyseren, "er een verhaal uithalen")
- visualiseren/presenteren
2. De aansluiting met informatiekunde
- alles is een lijstje (excel, zoterodatabase export)
- relationele database (access, sqlite)
- semantische structuur (html, css)
3. Doel van de sessie
De bedoeling van deze sessie is, ten eerste, inzicht verwerven in het verschil tussen gestructureerde data en ongestructureerde data. En ten tweede inzicht verwerven in het concept 'webscraping' en wat ervaring opdoen met een aantal scrapers.
Webscraping verduidelijken we door een aantal voorbeelden te tonen:
* eenvoudige Google spreadsheet functies
* een ingewikkelde scraper met Outwit Hub (Pro)
* de overzichtspagina van de Akutagawa literatuurprijs scrapen we op twee manieren
1. via een grafische interface: Outwit Hub
2. via een scrapy spider (python) vanaf de commandolijn
4. Alles is een lijstje: gestructureerde en ongestructureerde data
- gestructureerde data of datasets zijn lijstjes (in csv, xml, json ... formaat), data die opgeslagen is in databanken of semantisch getagde bestanden en
- met ongestructureerde data bedoelen we informatie die geen vooraf gedefinieerd data-model heeft of niet georganizeerd is in een voorgedefinieerde manier (html bijvoorbeeld)
5. Straight Data
De meest directe manier om aan gestructureerde data te geraken is via API's en websites die dit soort content aanbieden.
- Open Data (voorbeeld dataset)
- Voorbeeld datacataloog met gegevens over Japan
- een concept dat je in deze context vaak zal tegenkomen is "API": Application Programming Interface, een gestandaardiseerde manier om apps te laten omgaan met de aangeboden data
- data.go.jp
- Japan Open Data Charter Action Plan
- Verhalen vertellen met data:Tokyo Review, "Japan by the Numbers" rubriek

6. Webscraping: 'Your own robot'
It is rightfully said that “Data are becoming the new raw material of business”. World Wide Web or Internet is an ocean of data. However, most of the data on the web is in unstructured form and hence it requires a method and process to collect useful information from the web and transform it into structured, understandable and usable form. This is where web scraping comes into play.2
- Ongestructureerde data kan je structureren met tools. Eén categorie tools zijn scrapers.
- Web scraping heeft alles te maken met het zien van structuur in een webpagina en eigenlijk is het ook een vorm van search, namelijk het verzamelen van hoeveelheden gegevens waaruit je conclusies kan trekken.
6-1. Google spreadsheet function importHTML - tables en lists
=ImportHtml("http://mediawiki.arts.kuleuven.be/geschiedenisjapan//index.php/Tōdaiji", "table", 1)=ImportHtml("http://mediawiki.arts.kuleuven.be/geschiedenisjapan//index.php/Tōdaiji", "list", 6)-- aanloop naar 'structuur zien': deze functie zoekt naar html tags=ImportFeed("http://japanologie.arts.kuleuven.be/nl/rss.xml", "", "" ,3)
6-2. Wat als de data niet in een tabel of list staat en/of verspreid is over verschillende webpagina's?
- het centrale concept: structuur (en hoe die te lezen)
- ImportXML importeert data uit verschillende gestructureerde data types. XML, HTML, CSV, RSS ...
=IMPORTXML("https://www.w3schools.com/xml/simple.xml","breakfast_menu/food")
6-3. Zoeken naar structuur in HTML
- tags, attributen en waarden
- div,span | id,class : helpen te identificeren wat we precies willen parsen
=IMPORTXML("https://onderwijsaanbod.kuleuven.be/2016/opleidingen/n/SC_51016902.htm#bl=all","//li[@class='direct-content']//td[@class='opleidingsonderdeel']")- XPATH
6-3-1. Screencast Google spreadsheet functies
6-4. Voorbeeld waranwiki scraper
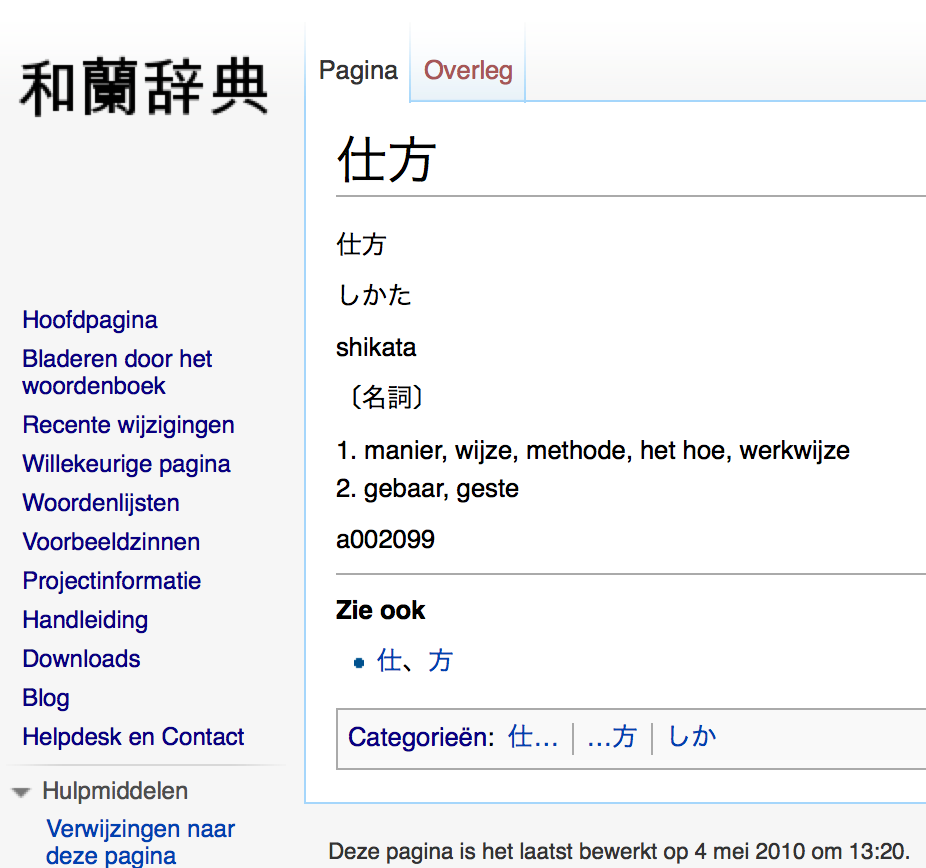
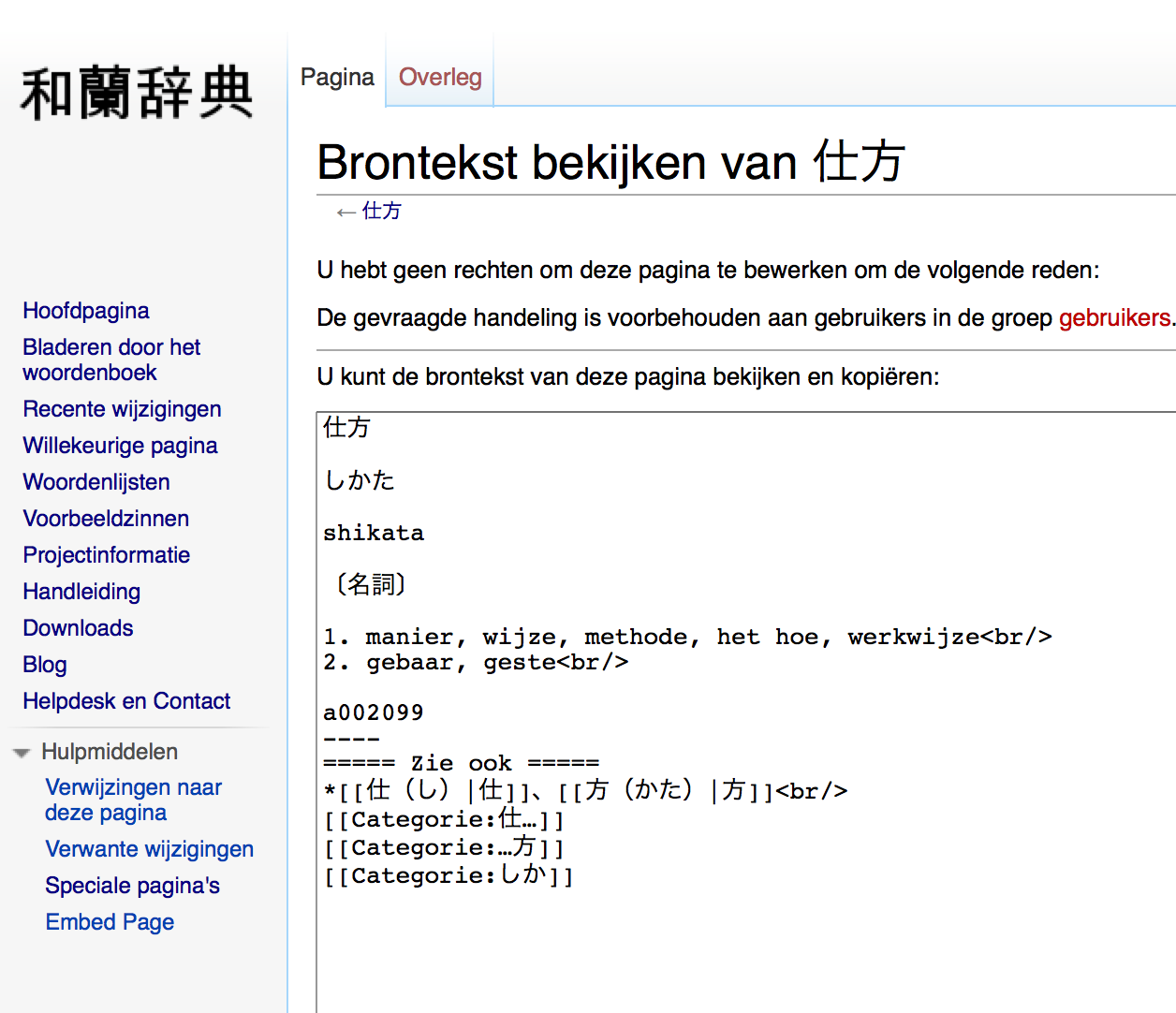
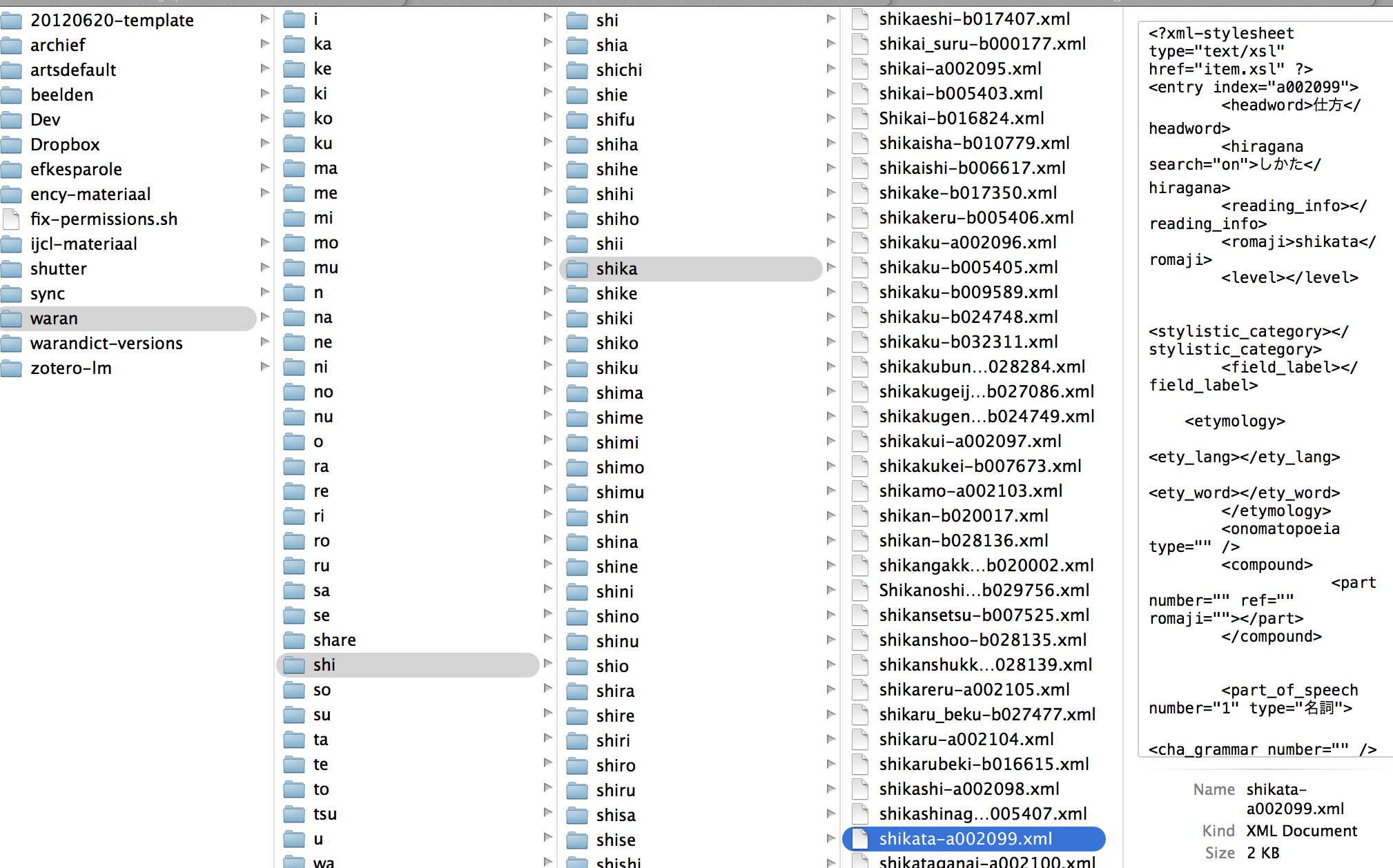
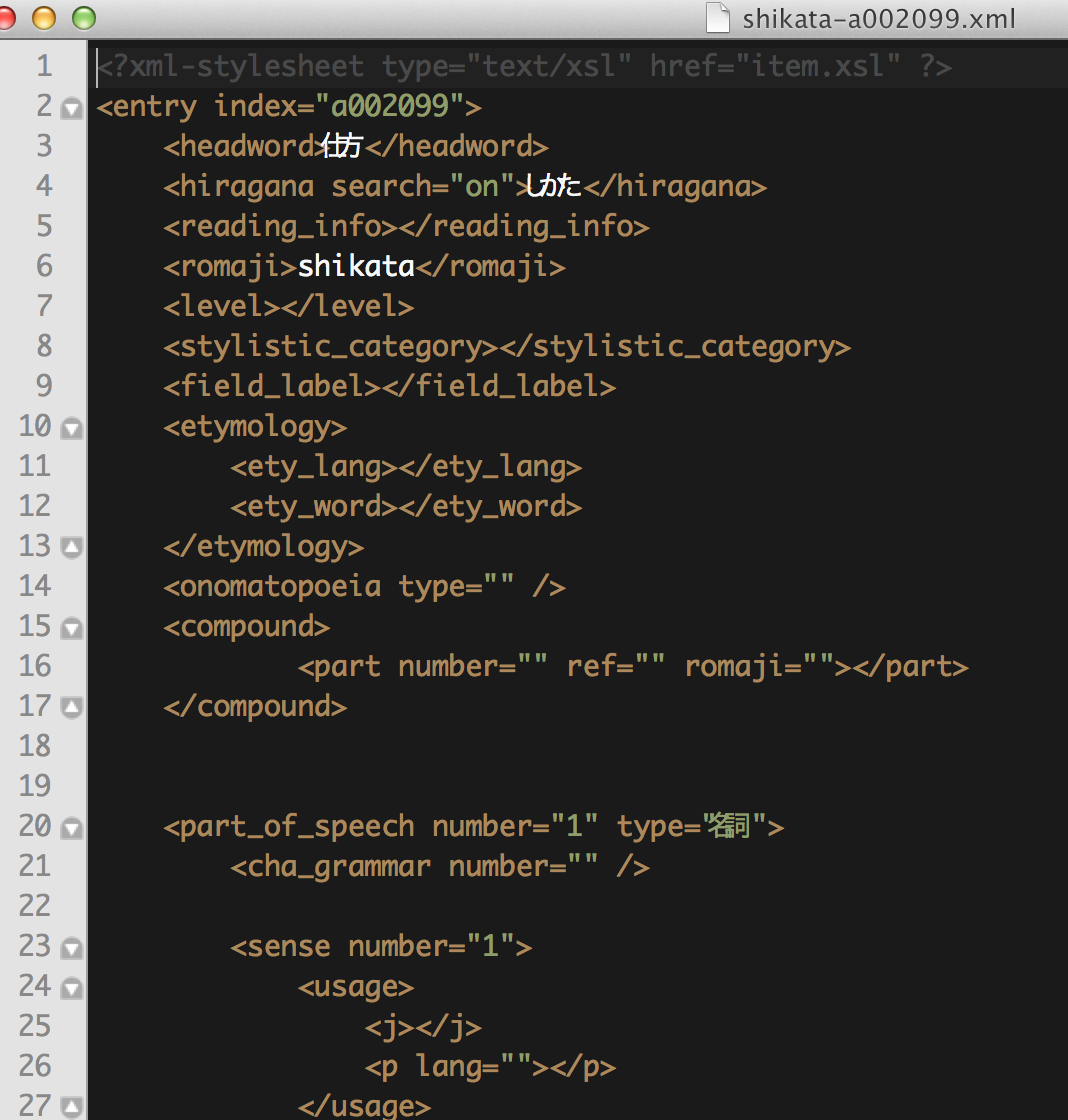


6-5. Scrapen van meerdere pagina's
- in google drive: zie tutorial/oefening "meerdere pagina's scrapen met google drive" 1
- met outwit hub
6-6. Scrapers op maat
6-6-1. Voorbeeld complexe scraper
How to collect profile info from Bloglovin with OutWit Hub Pro (12') - uit de OutWit Hub tutorials
- Doel: lijst genereren van blogs rond een bepaald thema
- Workflow:
- macro aanmaken om URL's van blogprofielen te verzamelen
- scraper aanmaken om specifieke informatie van een blogprofiel-pagina te halen
- tweede macro aanmaken die de scraper (2.) de lijst met URL's (1.) laat bezoeken en te exporteren als een excel bestand
- macro 1 en 2 consecutief laten uitvoeren
- Macro 1
- doel: al de relevante urls oplijsten
- 1.14 javascript afzetten (infinite scroll)
- URL leren lezen
bloglovin.com/blogs/3/16(3= pagina nummer, 16= categorie)- reguliere expressies
- /[1:XX/1]/16 : alle pagina's van categorie 16, vanaf pagina 1 tot de laatste pagina (XX) en telkens 1 pagina opschuiven (/1_)
- Scraper 4.19
- laad één profielpagina in
- maak nieuwe scraper
- bepaal welke stukken informatie je nodig hebt
- maak gebruik van html en css om 'markers' aan te geven 5.01
- 8.13 opkuisen is belangrijk
- Macro 2 9.14
- Link de URLS in macro 1 met de scraper
- exporteer naar excel
- Nieuwe job aanmaken 12.1
- 'new job'
- selecteer de macro's
- opslaan en
- starten (kijk naar de 'scraped' tab)
6-6-2. Eenvoudiger voorbeeld
- Akutagawa prijs met Outwit Hub
- te scrapen pagina
- screencast:
7. Programmeren = problem-solving
= slechts één stap verder
- trial and error (vaak sneller dan vragen of zoeken)
- Google it (vind documentatie)
- vind een stuk code dat werkt en pas het aan voor jouw doel (chap 12 scraping for journalists): googlenewsscrape,code
7-1. Python
- Wat is python?
- Voorbeeld: Dezelfde Akutagawa prijs - lijst winnaars
8. Oefeningen
Kies twee oefeningen uit de lijst:
- Welke data over onderwijs en Japan vind je op databank.worldbank.org, data.go.jp en e-stat.go.jp? Vergelijk ook het functioneren van de drie resources: in welke formaten kan je downloaden, hoe intuïtief is de navigatie ...
- vergelijk deze chrome scraping extensies
- schraap de lijst met bekende studenten van de Shōka sonjuku wikipagina - met een google spreadsheet functie
- schraap uit het programmaboek een tabel met de titels van alle OPO's, de link naar de inidviduele pagina van elke OPO en het aantal studiepunten
- schraap een lijst met alle nieuwe lemmata (+ hun urls) uit het Japans-Nederlands woordenboek
- schraap een lijst van het lab met unieke gebruikersnamen, de url van hun profielpagina en het moment waarop ze laatst ingelogd hebben (vermeld alleen de gebruikers die een waarde in de laatste kolom hebben)__
- schraap de lijst van de laatste 60 winnaars van de Naoki literaire prijs, met hun namen, de titel van het bekroonde werk en het jaar waarin werd gewonnen. Exporteer in XML-formaat.
9. Bronnen
- Bradshaw, Paul. 2012. Scraping for Journalists. Leanpub. http://leanpub.com/scrapingforjournalists.
- Russell, Matthew A. 2014. Mining the Social Web: Data Mining Facebook, Twitter, Linkedin, Google+, GitHub, and More. 2. ed. Beijing: O’Reilly.
- Bradshaw, Paul. 2018. The Online Journalism Handbook: Skills to Survive and Thrive in the Digital Age. Second edition. London; New York: Routledge.
- Heydt, Michael. 2018. Python Web Scraping Cookbook. Packt Books. https://www.packtpub.com/big-data-and-business-intelligence/python-web-s....