Tekstanalyse
- 1. Omgaan met Data - De data pijplijn
- 2. voorbeeld onderzoek op basis van dataset: maptap
- 3. data opkuisen
- 4. tekstanalyse en textmining
1. Omgaan met Data - De data pijplijn
We werken deze module uit in drie delen - één sessie per deel:
- data vinden/verwerven, aanmaken
- verwerken (converteren, opkuisen, mijnen, analyseren, "er een verhaal uithalen")
- visualiseren/presenteren
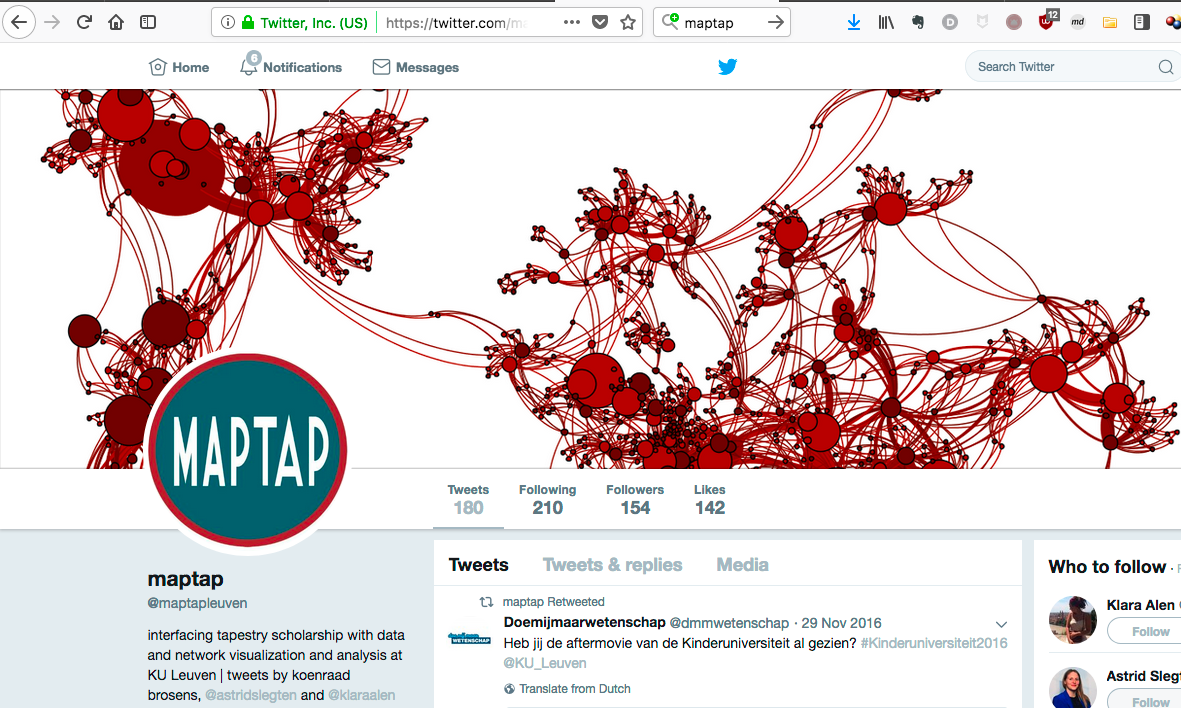
2. voorbeeld onderzoek op basis van dataset: maptap
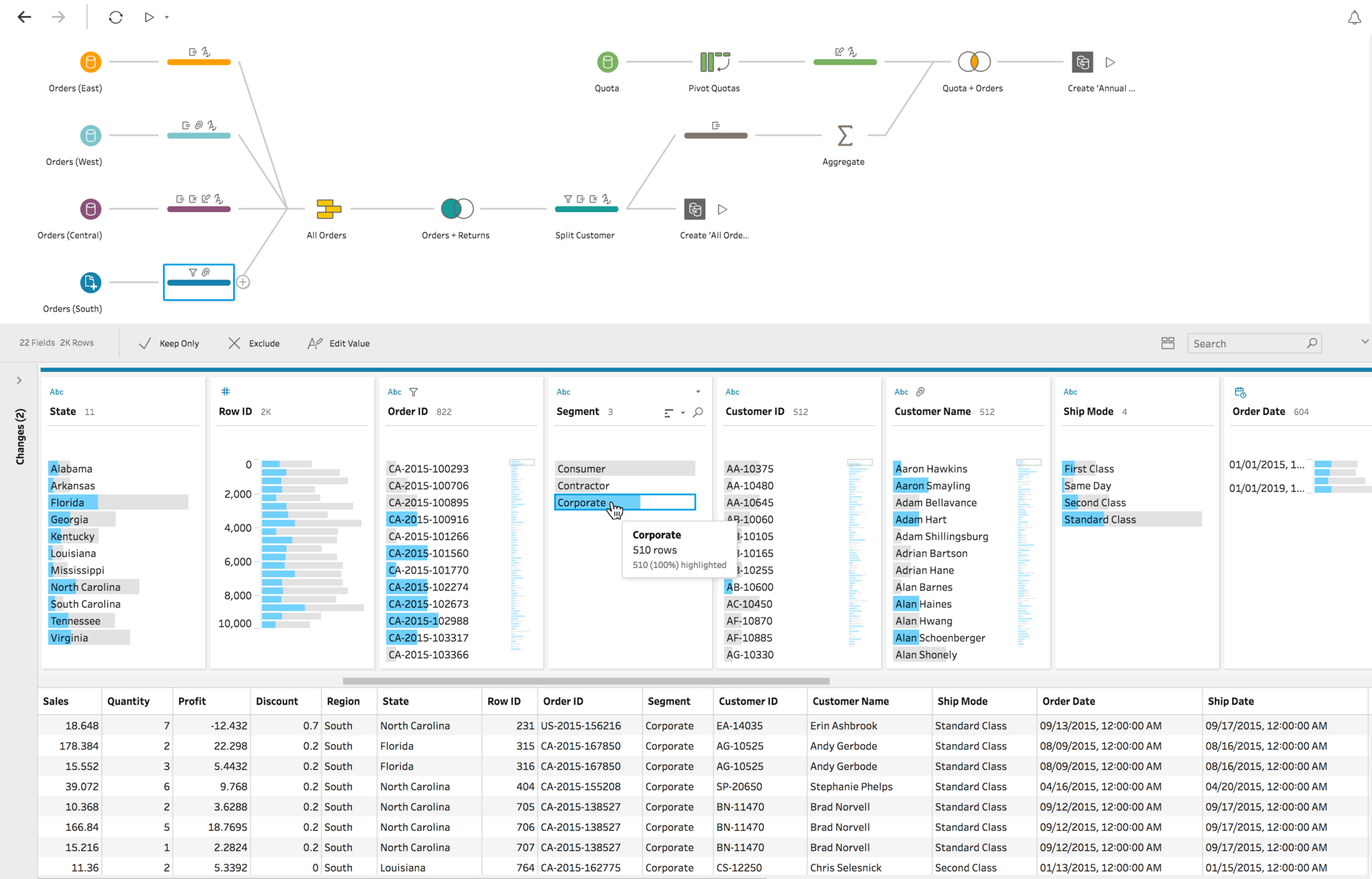
3. data opkuisen
All data is messy._
-
Tool: OpenRefine (voorbeeld)
-
Wat kan je ermee doen?
- witruimte verwijderen
- vooraan cel
- achteraan cel
- opeenvolgende witruimte (spatie te veel)
- speciale html karakters (entities) omzetten
- transformeren hoofd- en kleine letters
- normalizeren cijfers en andere formaten
- clustering
- cellen splitsen of samenvoegen (bv. adres)
- sorteren (maakt data makkelijker te manipuleren)
- faceting (enkel rijen tonen die beantwoorden aan bepaald criterium)
- duplicaten opsporen en verwijderen
- filteren (met regex)
- ...
- witruimte verwijderen
Snelle introductie: Bradshaw, Paul. 2011. “Cleaning Data Using Google Refine: A Quick Guide.” Online Journalism Blog. July 5, 2011. https://onlinejournalismblog.com/2011/07/05/cleaning-data-using-google-r....
20180430-clean_data_mdg18 from Hans Coppens on Vimeo.
Andere tool: TableauPrep
4. tekstanalyse en textmining
- Tekst is één van de meest voorkomende types data.
- tekstanalyse gaat over het omzetten van (grote hoeveelheden) tekst in gestructureerde data
- textmining is een set technieken om die data te modeleren en te zoeken naar trends, patronen ...
- woordfrequentie meten: n-gram
- jstor analyzer
- business intelligence
- sentiment analysis
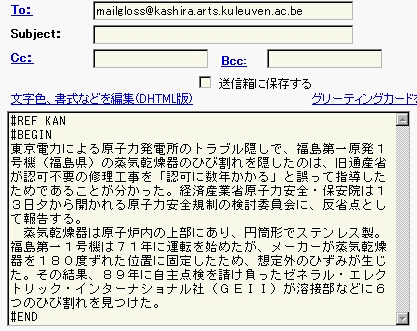
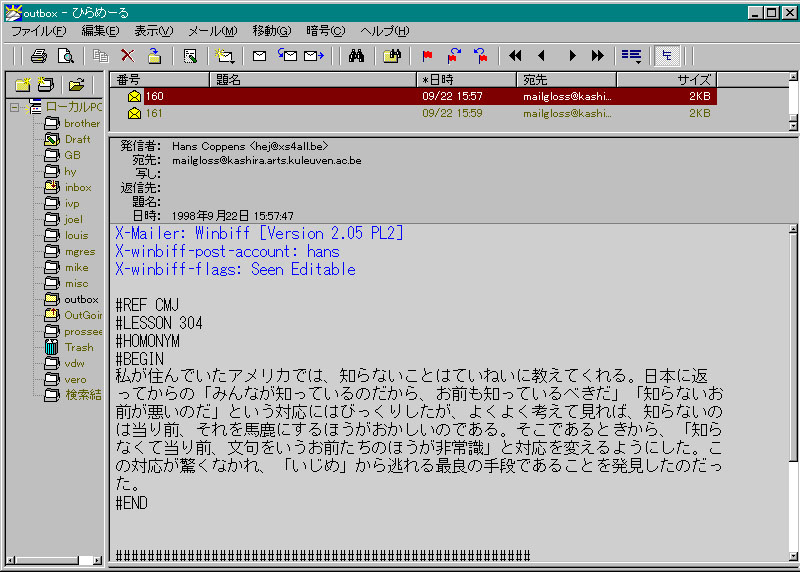
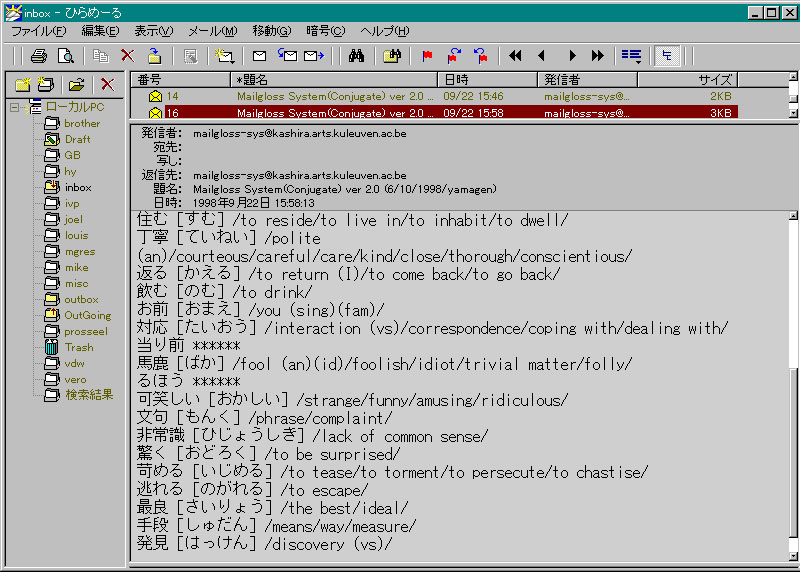
4-1. Mailgloss, NLP anno 1998
- mg-2.1.pl
- kan.dat (euc-jp encoding, atom: select encoding)
4-2. NLTK python library
- tokenization (lexicale analyse)
- stemming, lemmatization
- remove stop words (woorden met weinig contextuele betekenis)
- calculate frequency distributions
- remove punctuation marks
4-3. MeCab
-
Er zijn een paar hinderpalen bij de lexicale analyse van Japans. Hoe ga je segmenteren, de tekst opbreken in bruikbare deeltjes -- zonder spaties?
-
MeCab: Yet Another Part-of-Speech and Morphological Analyzer kan hierbij helpen.
4-3-1. Benodigdheden
- parser: MeCab
- dictionaries: MeCab-ipadic, MeCab-ipadic-neologd
- python library:mecab-python3
Tutorial: Fahey, Rob. 2016. “Japanese Text Analysis in Python.” @robfahey (blog). December 2, 2016. http://www.robfahey.co.uk/blog/japanese-text-analysis-in-python/.
4-3-2. 解析
20180503-mecab from Hans Coppens on Vimeo.
- Text voorwerken en lijst achteraf opkuisen.
- Non-tekst elementen verwijderen op voorhand:
- emoji,
- kaomoji (“(。ŏ﹏ŏ)”),
- (笑)
- Hashtags, stopwoorden, gebruikersnamen (@([a-z0-9_]+), URLs.
- Achteraf verwijderen spaties, interpunctie, ...
4-4. NVIVO
Text is meer dan tekst alleen.
-
brengt veel soorten bronnen bij mekaar: audio en video, interviews, enquetes, beelden, spreadsheet, pdf, social media materiaal ...
-
nvivo key terms
- "coderen" van bronnen (sources): verzamelen van materiaal volgens onderwerp, thema of case; organiseren van je materiaal
- nodes: containers voor query resultaten en gecodeerd materiaal
- cases: observatioe-eenheden (mensen,plaatsen, dingen)
- query
-
kan ook zotero info inlezen (RIS formaat)
- Jason Garrett. 2015. Using Zotero and Nvivo for Mac - Literature Review. https://www.youtube.com/watch?v=0wE8oEm1XZk.
- wat zotero niet kan: visualiseren van trends en relaties in je bronnen
- Work with pictures 3'13